两款大模型比较工具,助力AI构建工作
本期内容是针对大语言模型性能比较的,不是AI工具的比较,有一定的专业性,面向AI从业者和软件工程师,非从业者可以不用浪费时间看啦~
在AI大模型混战的时代,我们开发的AI应用,到底接入哪个大模型更好,并没有标准答案。
GPT4虽好,但苦在价格高,简单如翻译工作,不可能去调用gpt-4-turbo模型来完成,比雇一个专业的翻译还要贵。
Claude3长下文长度最长,能处理20万token的长文本,但是缺陷也在于此,明明一句话就能讲清楚的事情,他总是长篇累牍。
另外,在不同领域定向训练的专家模型,也都在其本领域有着远超通用模型的实力。
大模型到底怎么选?今天来给大家推荐两款大模型能力比对工具
ContextAI
这其实是一个对基于大模型构建的应用的压测平台,可以让帮助开发者在启动或更新应用程序之前对其进行压力测试。同时向你用程序发送大量模拟查询,并评估应用程序的表现。ContextAI使用LLM、自定义代码和人工评估者来评估响应。
其次,分析工具允许在生产中监控性能,了解真实用户如何体验你的产品。并按用例对用户进行分组,为每个用例显示成功指标,最终得出产品的强项和需要改进的地方。
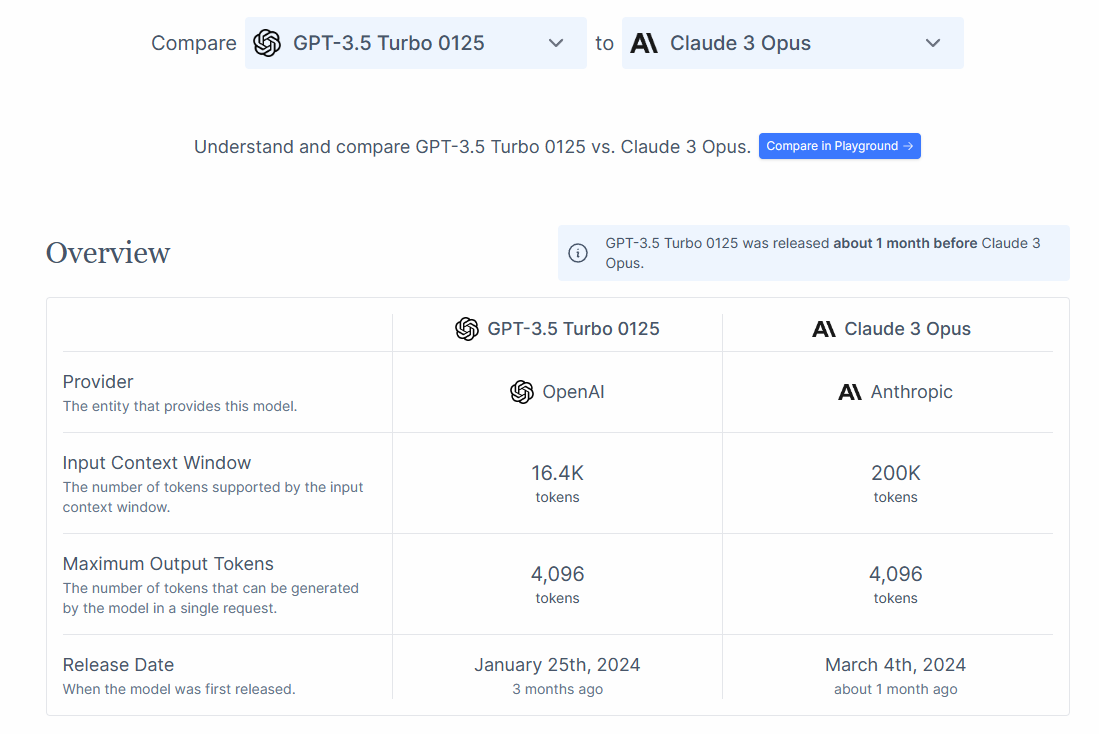
另外这个平台还有个非常好用的功能,是大模型性能对比,就像电商网站上比较两款相似产品性能一样,直观的看出不同模型之间的优劣和差异。
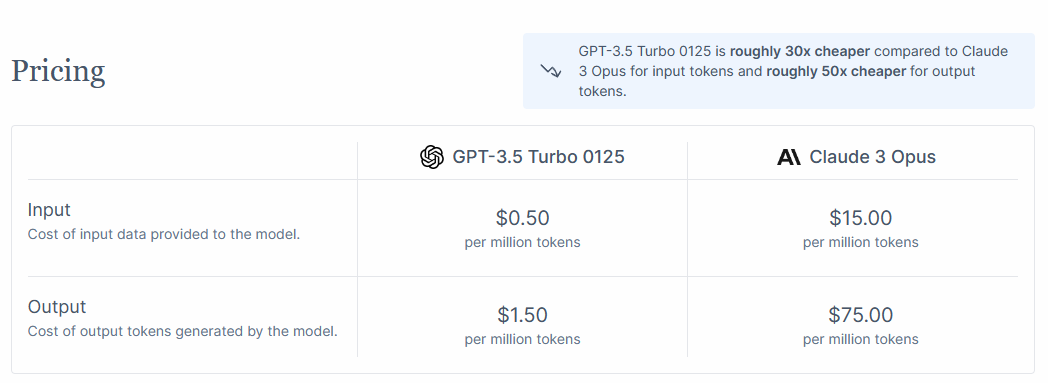
还贴心的附上了价格对比:
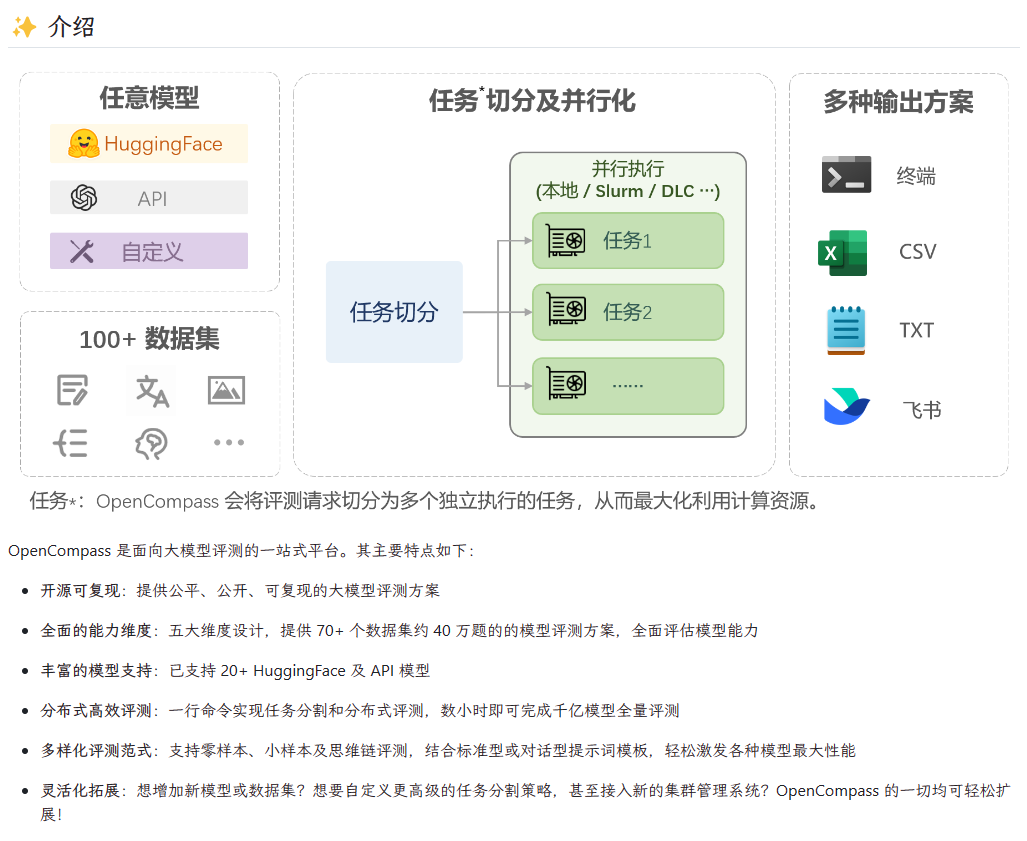
OpenCompass


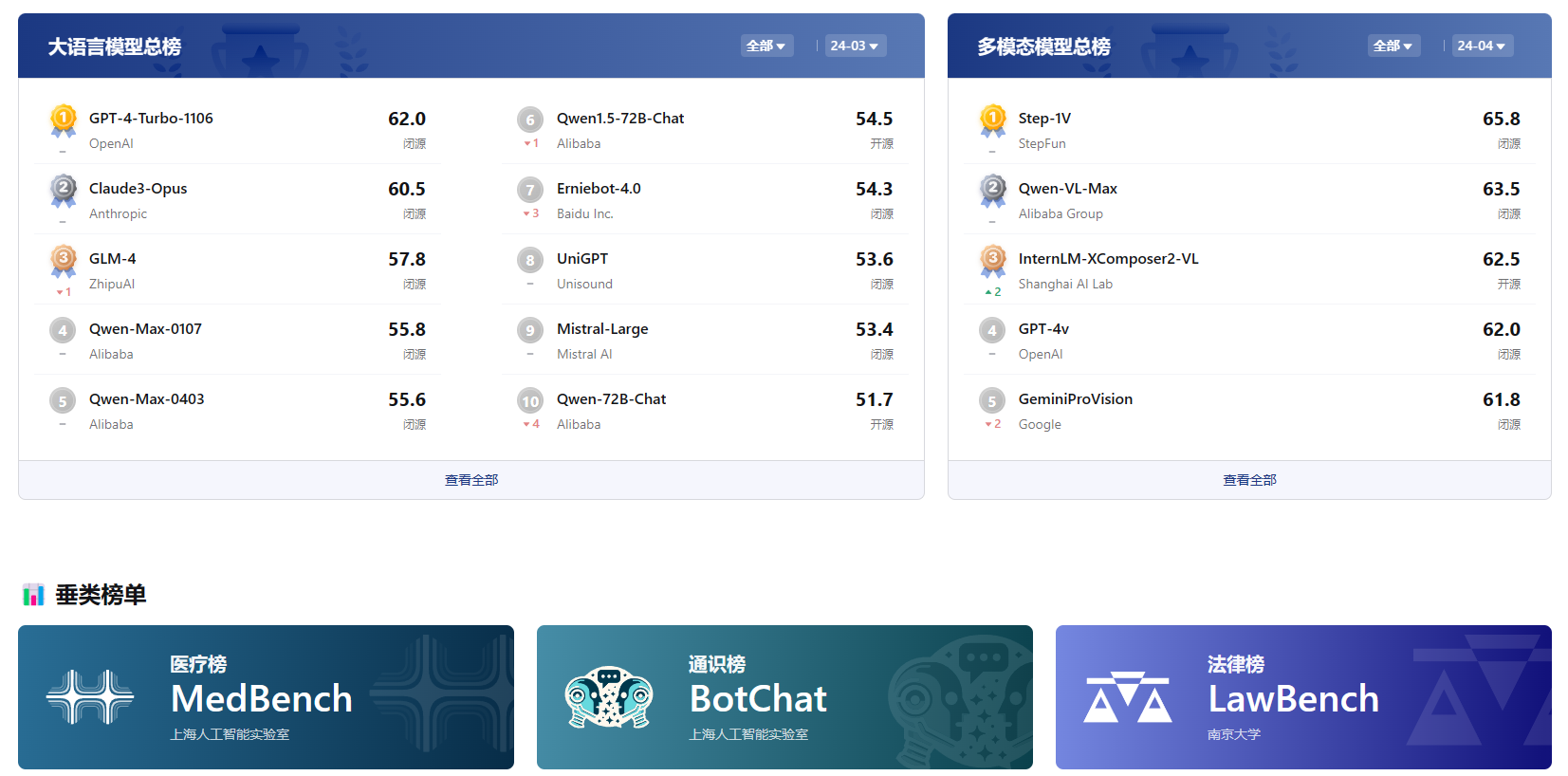
这是一款由上海人工智能实验室开源的大模型测评工具,涵盖学科、语言、知识、理解、推理等五个测评维度,可全面评估大模型能力。
网站提供评测榜单,包括总榜、多模态、和各类垂直领域榜单,如医疗、法律等。
这里值得一提的是GLM-4模型,也就是我们之前推荐过的智谱清言工具所使用的底层模型,以57.8的综合分数,荣登总榜第三,仅次于gpt4-turbo和claude3-opus。
如果你对他测评的榜单不满意,平台还提供开源免费的测评工具,支持本地部署,你可以用来测评出自己心目中的完美榜单!